
Tekninen hakukoneoptimointi tarkoittaa sivuston rakenteen, nopeuden ja indeksoitavuuden optimointia niin, että Google löytää, renderöi ja indeksoi jokaisen sivun oikein. Se kattaa crawlauksen hallinnan, Core Web Vitals -suorituskyvyn, canonical-tagit, schema-merkinnät, HTTPS-turvallisuuden ja sisäisen linkityksen.
Ilman toimivaa teknistä perustaa edes paras sisältö jää näkymättömiin. Ahrefs analysoi 1 miljoonaa domainia vuonna 2024: 95 % sivustoista sisälsi vähintään yhden teknisen SEO-ongelman. Tekninen SEO on se osa hakukoneoptimointia, jonka päälle kaikki muu rakentuu.
Mitä on tekninen hakukoneoptimointi?
Tekninen hakukoneoptimointi tarkoittaa sivuston rakenteen, nopeuden ja indeksoitavuuden optimointia niin, että hakukoneet löytävät, renderöivät ja indeksoivat jokaisen sivun oikein. Se kattaa crawlauksen hallinnan, Core Web Vitals -suorituskyvyn, canonical-tagit, schema-merkinnät, HTTPS-turvallisuuden ja sisäisen linkityksen. Ilman toimivaa perustaa edes paras sisältö jää näkymättömiin.
Käytännössä tekninen SEO käsittelee kolmea peruskysymystä:
- Löytääkö Google sivusi? (crawlaus)
- Ymmärtääkö Google sivusi sisällön? (renderöinti ja rakennedata)
- Tarjoaako sivusi hyvän käyttäjäkokemuksen? (nopeus, mobiili, turvallisuus)
Tekninen SEO ei tarkoita sisällön kirjoittamista tai linkkien rakentamista. Se tarkoittaa infrastruktuuria: samaa kuin sähköt ja vesijohto talossa. Kukaan ei muuta taloon sähköjen takia, mutta ilman niitä mikään muu ei toimi.
Teknisen hakukoneoptimoinnin osa-alueet
Tekninen hakukoneoptimointi ei ole yksi yksittäinen asetus, vaan joukko tarkistuksia, jotka vaikuttavat samaan lopputulokseen: tärkeät sivut löytyvät, Google ymmärtää ne oikein ja käyttäjä saa sivun auki ilman kitkaa.
Pk-yritykselle tärkein ajatus on priorisointi. Ensin korjataan asiat, jotka estävät indeksoinnin tai rikkovat sivun käytön. Vasta sen jälkeen hiotaan yksityiskohtia.
| Osa-alue | Mitä tarkistetaan | Miksi sillä on väliä |
|---|---|---|
| Crawlaus ja indeksointi | robots.txt, sitemap, noindex, GSC Coverage | Google ei voi rankata sivua, jota se ei löydä tai lisää indeksiin |
| Canonical ja duplikaatit | self-referencing canonicalit, URL-variantit, parametrit | Link equity ei hajaannu useaan versioon samasta sisällöstä |
| URL-rakenne | lyhyet, kuvaavat ja pysyvät URLit | Käyttäjä ja Google ymmärtävät sivun aiheen jo osoitteesta |
| Title ja metakuvaus | uniikit title-tagit, meta descriptionit ja SERP-esikatselu | Parantaa relevanssia ja klikkausprosenttia hakutuloksissa |
| Nopeus ja Core Web Vitals | LCP, INP, CLS, TTFB ja renderöinti | Hidas sivu pudottaa käyttökokemusta ja voi heikentää sijoituksia |
| Kuvien optimointi | formaatti, koko, alt-teksti, lazy load, mitat | Suuret kuvat ovat yleisin LCP-ongelman aiheuttaja |
| Mobiilikäytettävyys | responsiivisuus, tap targetit, sisältö mobiilissa | Google arvioi ensisijaisesti mobiiliversiota |
| Rakennedata | Article, BreadcrumbList, Organization, Service, FAQ | Auttaa Googlea ja AI-hakuja tulkitsemaan sivun entiteetit |
| Sisäinen linkitys | crawl depth, orphan-sivut, ankkuritekstit | Jakaa auktoriteettia tärkeille sivuille ja auttaa crawlauksessa |
Teknisen SEO:n perustan tarkistus
Jos sivuston tekninen perusta on epäselvä, aloita näistä. Ne kertovat nopeasti, onko ongelma kriittinen vai lähinnä optimointityötä.
| Tarkistus | Hyvä merkki | Hälytysmerkki |
|---|---|---|
| Google Search Console | Tärkeät sivut ovat indeksissä ja virheitä on vähän | Sitemapissa sivuja, mutta Google ei indeksoi niitä |
| Sitemap | Sisältää vain julkaistut, indeksoitavat sivut | Sitemapissa on 404-sivuja, redirectejä tai noindex-sivuja |
| Robots.txt | Ei estä CSS-, JS-, kuva- tai sisältöpolkuja | Tärkeät kansiot on estetty vahingossa |
| Canonical | Jokaisella sivulla on oikea self-referencing canonical | Canonical osoittaa väärään sivuun tai noindex-sivuun |
| Nopeus | LCP alle 2,5 s ja CLS alle 0,1 mobiililla | Hero-kuva, fontit tai skriptit viivästyttävät latausta |
| Sisäiset linkit | Jokainen tärkeä sivu löytyy 1-3 klikkauksella | Tärkeitä sivuja ei linkitetä mistään |
Crawlaus ja indeksointi
Crawlaus on teknisen SEO:n lähtöpiste: jos Google ei löydä sivujasi, se ei voi indeksoida niitä.
Googlen crawler (Googlebot) käy läpi sivustosi seuraamalla linkkejä sivulta toiselle. Se ei automaattisesti löydä kaikkia sivuja. Sinun tehtäväsi on varmistaa, että Googlebot löytää oikeat sivut ja jättää turhat rauhaan.
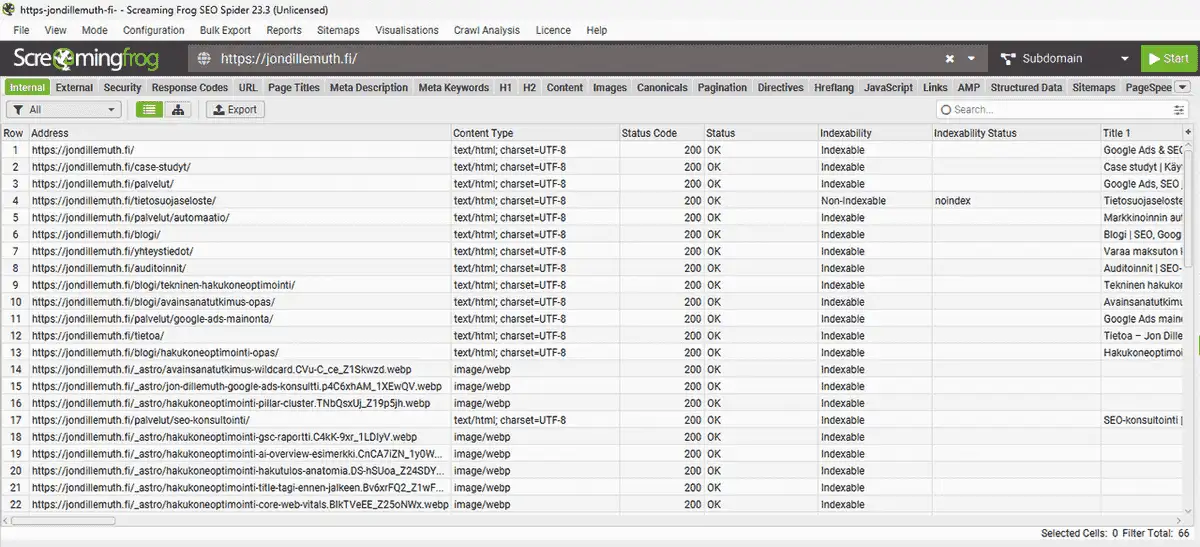
Esimerkki omalta sivustoltamme: Screaming Frog -crawl (19.4.2026) löysi 238 sisäistä URL:a, joista 33 on HTML-sivuja ja 202 kuvia. Crawlausaika 3 minuuttia, 99,6 % vastauksista alle 1 sekunnissa. 0 sivua blocked by robots.txt. Tämä on terve pohja: Googlebot pääsee kaikkialle, eikä aikaa tuhlaannu turhiin URL-variantteihin.
Robots.txt
Robots.txt on tekstitiedosto sivuston juuressa, joka kertoo hakukoneille mihin niillä on pääsy. Se ei ole turvamekanismi (Google voi silti indeksoida estetyn sivun, jos siihen linkitetään muualta), vaan crawlauksen ohjaustyökalu.
Tärkeimmät säännöt:
- Allow: / sallii kaiken crawlauksen (oletus useimmilla sivustoilla)
- Disallow: /admin/ estää hallintapaneelin crawlauksen
- Sitemap: rivi kertoo hakukoneille missä sivukartta on
Yleinen virhe: robots.txt estää CSS- tai JavaScript-tiedostoja, jolloin Google ei pysty renderöimään sivua oikein. Tarkista Google Search Consolen URL Inspection -työkalulla, näkeekö Google sivun samalla tavalla kuin käyttäjä.
Tämän sivuston robots.txt (tiivistetysti):
User-agent: *
Allow: /
Sitemap: https://jondillemuth.fi/sitemap-index.xml
# AI-crawlerit sallittu (tietoinen päätös)
# Täydellinen lista: GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot,
# Google-Extended, Applebot-Extended, Meta-ExternalAgent, Bytespider, Amazonbot
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /Huomaa: AI-crawlerit on sallittu erikseen, koska oletusarvoisesti osa CDN-palveluista (esim. Cloudflare) estää ne. Eksplisiittinen Allow varmistaa, ettei mikään taso estä niitä.
XML-sitemap
Sitemap on lista kaikista sivuista, jotka haluat Googlen indeksoivan. Se ei takaa indeksointia, mutta nopeuttaa uusien sivujen löytämistä ja auttaa Googlea ymmärtämään sivuston rakenteen.
Hyvän sitemapin ominaisuudet:
- Sisältää vain indeksoitavat sivut (ei noindex-sivuja, ei uudelleenohjauskohteita)
- Lastmod-päivämäärä on oikea (ei päivity automaattisesti joka build, vaan sisällön muuttuessa)
- Viittaus robots.txt:ssä:
Sitemap: https://domain.fi/sitemap.xml - Lähetetty Google Search Consoleen
- IndexNow-protokolla: Bing ja Yandex tukevat IndexNow-rajapintaa, joka ilmoittaa hakukoneille uudesta tai muuttuneesta sisällöstä välittömästi. Google ei tue IndexNow:ta (vielä), mutta Bingissä se nopeuttaa indeksointia merkittävästi. WordPress-pluginit ja Cloudflare tukevat IndexNow:ta automaattisesti.
XML-sivukartta ja indeksoinnin hallinta
Tarkista sitemap aina teknisen auditoinnin alussa:
- Sitemap aukeaa selaimessa ilman virhettä
- Kaikki URLit palauttavat 200-statuksen
- Sitemapissa ei ole
noindex-sivuja, canonicalin ohittamia sivuja tai uudelleenohjauksia lastmodmuuttuu vain silloin, kun sisältö oikeasti muuttuu- Sitemap on lähetetty Search Consoleen ja Google on lukenut sen äskettäin
- Robots.txt viittaa oikeaan sitemap-osoitteeseen
Indeksointiongelmat
Google Search Consolen Coverage-raportti kertoo, mitkä sivut on indeksoitu ja mitkä ei.
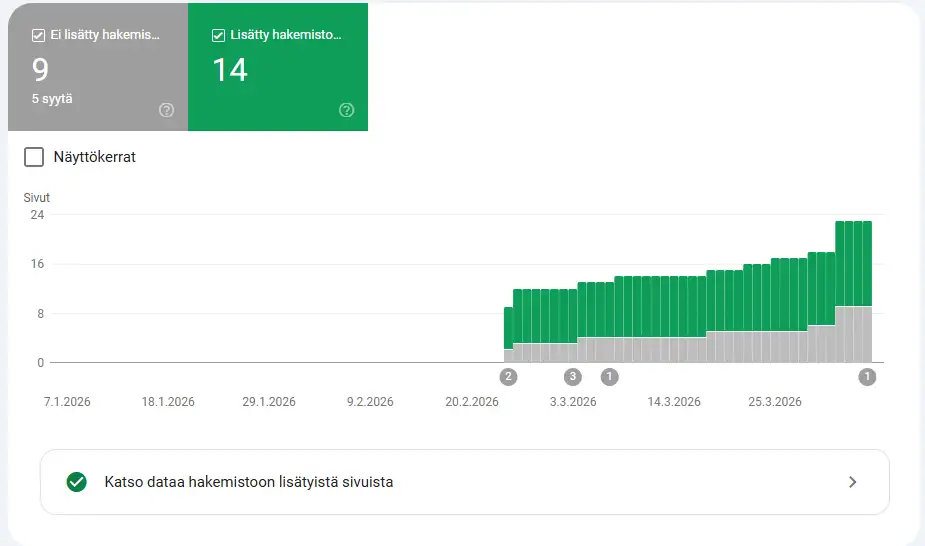
Indeksointiesimerkki: jondillemuth.fi:n indeksointisuhde huhtikuussa 2026: 32 sivua sitemapissa, kaikki 32 indeksoitu = 100 %. GSC Coverage -raportissa 0 virhettä, 0 “Indexable URL Not Indexed” -merkintää. Tämä johtuu kolmesta asiasta: sitemap sisältää vain indeksoitavat sivut, jokainen sivu saa vähintään yhden sisäisen linkin eikä mikään sivu ole noindex-tilassa vahingossa.
Yleisimmät syyt siihen, ettei sivua indeksoida:
| Syy | Ratkaisu |
|---|---|
| Noindex-merkintä | Poista meta robots noindex, jos sivu pitäisi indeksoida |
| Canonical osoittaa toiseen sivuun | Tarkista, onko canonical oikein |
| Soft 404 | Sivu palauttaa 200 mutta sisältö on tyhjä tai virhesivu |
| Crawlausvirhe | Palvelin palauttaa 5xx tai timeout |
| Ohut sisältö | Google ei pidä sivua riittävän arvokkaana indeksoitavaksi |
Canonical-tagit
Canonical-tagi kertoo Googlelle, mikä on sivun ensisijainen versio. Tämä on kriittistä, koska sama sisältö voi olla saatavilla useasta osoitteesta:
https://domain.fi/sivujahttps://domain.fi/sivu/(trailing slash)http://jahttps://www.ja ilman- URL-parametrien kanssa:
?ref=email,?utm_source=linkedin
Ilman canonicalia Google saattaa jakaa sivun “arvovallan” (link equity) näiden kaikkien versioiden kesken sen sijaan, että keskittäisi sen yhteen.
Oikea toteutus
Jokainen sivu sisältää self-referencing canonicalin:
<link rel="canonical" href="https://domain.fi/blogi/artikkeli/" />Self-referencing tarkoittaa, että sivu osoittaa itseensä. Tämä on suositeltu käytäntö myös sivuille, joilla ei ole duplikaatteja, koska se poistaa epävarmuuden.
Omasta datasta: Screaming Frog -crawl (19.4.2026): 32/32 sivua sisältää self-referencing canonicalin. 0 puuttuvia, 0 ristiriitaisia, 0 suhteellisia. Astro-konfiguraatiossa trailingSlash: "always" normalisoi trailing slashit, ja canonical generoidaan automaattisesti build-vaiheessa. Tämä eliminoi koko ongelmakategorian kerralla.
Yleiset virheet
- Suhteellinen canonical (
<link rel="canonical" href="/">): toimii, mutta absoluuttinen URL on varmempi - Canonical osoittaa noindex-sivuun: Google saa ristiriitaisen signaalin
- Canonical osoittaa eri sisältöön: Google voi ohittaa sen kokonaan
- Canonical puuttuu: Google arvaa itse, mikä on ensisijainen versio
URL-rakenne
Hyvä URL-rakenne kertoo sekä Googlelle että käyttäjälle, mistä sivulla on kyse, ennen kuin kumpaakaan on avattu.
URL-rakenne vaikuttaa siihen, miten Google ymmärtää sivustosi hierarkian ja miten käyttäjät hahmottavat sijaintinsa sivustolla.
Tämän sivuston URL-rakenne: Kolme tasoa, selkeä hierarkia. Palvelut: /palvelut/hakukoneoptimointi-yritykselle/. Blogi: /blogi/tekninen-hakukoneoptimointi/. Auditoinnit: /auditoinnit/jurreblom-nl-seo-auditointi/. Jokainen URL on alle 60 merkkiä, sisältää pääavainsanan ja käyttää väliviivoja. Screaming Frog -crawlissa 0 URL:a parametreilla, 0 isoilla kirjaimilla, 0 erikoismerkeillä.
Hyvän URL:n periaatteet
- Lyhyt ja kuvaava:
/palvelut/hakukoneoptimointi-yritykselle/kertoo heti mistä on kyse - Avainsana mukaan: pääavainsana URL:ssa vahvistaa relevanssisignaalia
- Looginen hierarkia:
/blogi/tekninen-hakukoneoptimointi/on parempi kuin/p/12345/ - Pienaakkoset, väliviivat:
tekninen-hakukoneoptimointieikäTekninen_Hakukoneoptimointi - Ei turhia parametreja:
/tuote/koulutus/?ref=email&session=abc123sekoittaa indeksointia
Käyttäjäystävälliset URLit ja permalinkit
Käyttäjäystävällinen URL on pysyvä, luettava ja helppo jakaa. Tarkista erityisesti nämä:
| Tarkistus | Hyvä toteutus | Riski |
|---|---|---|
| Pituus | /blogi/tekninen-hakukoneoptimointi/ | Pitkä polku, jossa on päivämäärä, kategoria ja turhia sanoja |
| Merkistö | pienaakkoset, a-z, numerot ja väliviivat | ääkköset, isot kirjaimet, alaviivat tai erikoismerkit |
| Hierarkia | tärkeä sivu 1-3 tasossa | syvä polku, joka ei näy navigaatiossa |
| Pysyvyys | URL ei muutu otsikon pienen päivityksen takia | vuosiluku tai kampanjanimi pakottaa myöhemmin redirectin |
Yleiset virheet
- WordPress-oletusrakenne
/?p=123tai/archives/123: vaihda asetuksista muotoon/%postname%/ - Liian syvät URL:t
/kategoria/alakategoria/ala-alakategoria/sivu/: pidä hierarkia matalana (max 3 tasoa) - Päivämäärä URL:ssa
/2026/04/artikkeli/: vanhenee visuaalisesti ja pidentää URL:a turhaan - Suomenkieliset merkit URL:ssa (ä, ö): selaimet ja hakukoneet tukevat niitä, mutta translitterointi (a, o) on turvallisempaa linkkien jakamisen kannalta
Title, metakuvaus ja hakutuloksen ulkoasu
Title ja metakuvaus eivät ole pelkkää copywritingia. Ne ovat myös tekninen tarkistus: generoiko sivusto jokaiselle indeksoitavalle sivulle uniikin titlen, oikean canonicalin ja hakutuloksessa toimivan kuvauksen?
Hyvä title kertoo sivun pääaiheen ja rajaa hakijan odotuksen. Hyvä metakuvaus selittää, miksi sivu kannattaa avata. Google voi silti kirjoittaa kuvauksen uudelleen, mutta oma metakuvaus antaa lähtökohdan.
| Elementti | Tarkistus | Korjaus |
|---|---|---|
| Title | Jokaisella indeksoitavalla sivulla on uniikki title | Luo title template ja tarkista duplikaatit Screaming Frogilla |
| H1 | Sivulla on yksi pääotsikko, joka vastaa sivun aihetta | Älä tee useita H1-otsikoita komponenttien sisään |
| Meta description | Kuvaus on uniikki ja vastaa hakuintenttiin | Kirjoita palvelu- ja artikkelisivuille käsin, älä generoi kaikille samaa |
| SERP-ulkoasu | Title ei katkea pahasti ja kuvaus lupaa oikean asian | Testaa tärkeimmät sivut SERP preview -työkalulla |
Title-tagia ei kannata optimoida irrallaan sisällöstä. Jos title lupaa “teknisen SEO:n tarkistuslistan”, sivulla pitää olla oikea tarkistuslista. Muuten CTR voi nousta hetkeksi, mutta käyttäjä poistuu nopeasti.
Duplikaattisisältö
Duplikaattisisältö hajottaa sivun auktoriteetin useaan URL-osoitteeseen sen sijaan, että kaikki link equity keskittyisi yhteen.
Duplikaattisisältö tarkoittaa tilannetta, jossa sama tai lähes sama sisältö on saatavilla useasta eri URL-osoitteesta. Tämä on yksi yleisimmistä teknisen SEO:n ongelmista, ja se ei aina johdu kopioinnista. Usein sivuston tekniikka tuottaa duplikaatteja itsestään.
Omasta datasta: Screaming Frog (19.4.2026): 0 exact duplicates, 0 near duplicates, 0 semantically similar -sivua. Tämä johtuu kolmesta konfiguraatiosta: trailing slash -normalisointi (trailingSlash: "always"), self-referencing canonicalit jokaisella sivulla ja HTTPS-only (HTTP ohjaa 301:llä). Nämä kolme asetusta eliminoivat yleisimmät duplikaattilähteet automaattisesti.
Miten duplikaatit syntyvät
- www vs ei-www:
www.domain.fi/sivu/jadomain.fi/sivu/ovat Googlelle kaksi eri sivua - HTTP vs HTTPS: samat sivut molemmissa protokollissa
- Trailing slash:
/sivuja/sivu/ - URL-parametrit:
?sort=price,?page=1,?utm_source=emailluovat uusia URL-variantteja - Verkkokauppa: sama tuote useassa kategoriassa (
/miehet/kengat/nike/ja/nike/kengat/) - Tulostusnäkymät:
/sivu/print/on kopio alkuperäisestä
Miksi duplikaatit ovat ongelma
- Link equity hajaantuu: ulkoiset linkit jakautuvat eri versioiden kesken sen sijaan, että keskittyisivät yhteen
- Crawl budget tuhlaantuu: Google crawlaa samaa sisältöä usealta URL:lta
- Google valitsee väärän version: hakutuloksissa saattaa näkyä versio, jota et halua
Ratkaisut
| Ongelma | Ratkaisu |
|---|---|
| www vs ei-www | 301-uudelleenohjaus yhteen versioon + GSC:ssä oikea versio |
| HTTP vs HTTPS | 301 kaikesta HTTP-liikenteestä HTTPS:ään |
| URL-parametrit | Canonical-tagi osoittaa parametrittomaan versioon |
| Verkkokaupan tuoteduplikaatit | Canonical osoittaa pääkategoriaan, tai noindex muille |
| Ohut/turha duplikaatti | 301-uudelleenohjaus pääversioon tai noindex |
Thin content: sivut, joilla on liian vähän sisältöä
Thin content tarkoittaa sivuja, joilla on niin vähän tekstiä, ettei Google pidä niitä riittävän arvokkaana indeksoitavaksi tai rankkaamaan hyvin. Tämä ei ole sama asia kuin duplikaattisisältö, mutta ratkaisu riippuu samalla tavalla sivutyypistä.
| Sivutyyppi | Ratkaisu |
|---|---|
| Listasivu (blogi-index, kategoria) | Lisää kuvaava intro-teksti (2–3 kappaletta), joka kertoo, mitä aiheita kategoria kattaa |
| Turha sivu (arkisto, tagi, parametrisivu) | Noindex, tai poista kokonaan |
| Arvokas mutta ohut sivu (palvelusivu, tuotesivu) | Kirjoita lisää substanssia: mitä palvelu sisältää, kenelle se sopii, mitä tuloksia odottaa |
| Generoitu sivu (suodatinvariantti) | Canonical pääversioon tai noindex |
Omasta datasta: Screaming Frog -crawlissa (19.4.2026) löytyi 4 sivua alle 200 sanaa. Nämä ovat listasivu-tyyppisiä sivuja (blogi-index, palvelut-index, case-studyt-index ja auditoinnit-index). Korjaus: lisätään jokaiseen kuvaava intro-teksti, joka selittää mitä kyseinen osio sisältää ja kenelle se on suunnattu.
Miten Core Web Vitals vaikuttaa hakutulossijoituksiin?
Core Web Vitals on Googlen mittaristo, joka arvioi sivuston käyttäjäkokemuksen kolmella mittarilla: LCP (latausnopeus), INP (reagointinopeus) ja CLS (visuaalinen vakaus). Huono CWV-tulos voi pudottaa sijoituksia, koska Google käyttää kenttädataa suorana rankkaussignaalina. Tavoitteet mobiililla: LCP alle 2,5 s, INP alle 200 ms, CLS alle 0,1.
Core Web Vitals koostuu kolmesta mittarista, jotka kaikki vaikuttavat hakutulossijoituksiin:
LCP (Largest Contentful Paint)
Mittaa kuinka nopeasti sivun suurin näkyvä elementti (yleensä hero-kuva tai otsikko) latautuu.
Tavoite: alle 2,5 sekuntia mobiililla. Google ja SOASTA mittasivat, että 53 % käyttäjistä poistuu sivulta, jos lataus kestää yli 3 sekuntia (2017).
Yleisimmät LCP-ongelmat ja ratkaisut:
| Ongelma | Ratkaisu |
|---|---|
| Suuret kuvat | WebP-muoto, srcset eri kokoisille näytöille, lazy load (paitsi hero) |
| Hidas palvelin (TTFB) | CDN, staattinen generointi, edge caching |
| Render-blocking CSS/JS | Inline kriittinen CSS, defer JavaScript |
| Web-fontit | font-display: swap tai optional, preload-vihje |
| Kolmannen osapuolen skriptit | Lataa GTM, analytiikka ja mainokset asynkronisesti |
INP (Interaction to Next Paint)
Mittaa kuinka nopeasti sivu reagoi käyttäjän toimintaan (klikkaus, näppäinpainallus, kosketustoiminto). Korvasi FID:n (First Input Delay) maaliskuussa 2024.
Tavoite: alle 200 millisekuntia.
INP on yleensä ongelma sivustoilla, joilla on raskas client-side JavaScript (React, Vue, Angular SPA:t). Staattisilla sivustoilla (Astro, Hugo, plain HTML) INP on harvoin ongelma. (Googlen INP-dokumentaatio)
CLS (Cumulative Layout Shift)
Mittaa kuinka paljon sivun elementit hyppivät latauksen aikana. Jos mainos latautuu ja työntää tekstiä alaspäin, tai kuva latautuu ilman varattua tilaa, se aiheuttaa layout shiftejä.
Tavoite: alle 0,1.
Ratkaisut:
- Kaikilla kuvilla width ja height -attribuutit (tai CSS aspect-ratio)
- Mainospaikoille kiinteä tila varattu CSS:llä (min-height)
- Fontit: font-display: optional tai swap + preload (estää FOIT/FOUT-hyppyjä)
- Dynaamisesti ladattava sisältö: varaa tila etukäteen
Sivuston nopeuden mittaamisen tarkistuslista
Nopeutta ei kannata arvioida pelkän Lighthouse-pistemäärän perusteella. Mittaa sekä käyttäjädata että tekninen juurisyy.
| Mittari | Mistä katsotaan | Mitä se kertoo |
|---|---|---|
| LCP | PageSpeed Insights, GSC Core Web Vitals | Kuinka nopeasti pääsisältö näkyy käyttäjälle |
| INP | CrUX, GSC Core Web Vitals | Reagoiko sivu nopeasti klikkauksiin ja napautuksiin |
| CLS | PageSpeed Insights, Lighthouse | Hyppiikö layout latauksen aikana |
| TTFB | WebPageTest, Lighthouse, palvelinlogit | Hidastaako palvelin ennen kuin sivu alkaa latautua |
| Render-blocking resources | Lighthouse ja DevTools Network | Estävätkö CSS, fontit tai skriptit sivun piirtymistä |
Korjaa ensin suurin pullonkaula. Jos LCP-elementti on 800 kilotavun kuva, JavaScriptin siivoaminen ei ratkaise pääongelmaa. Jos TTFB on korkea, kuvien pakkaaminen ei poista palvelimen hitautta.
Käytännön esimerkki: jondillemuth.fi
Tämä sivusto on rakennettu Astro-frameworkilla (staattinen HTML, ei client-side frameworkia). Lähtötilanne julkaisun jälkeen oli mobiililla 93/100 ja desktopilla 99/100:
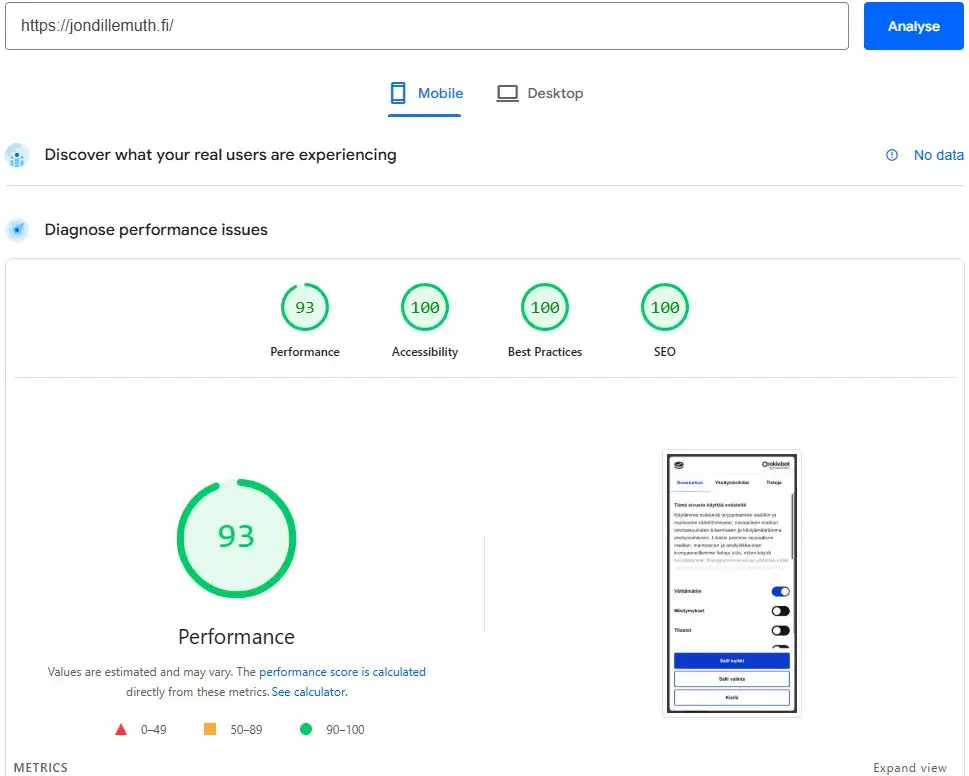
Optimoinnin jälkeen tulos on 100/100 molemmilla:
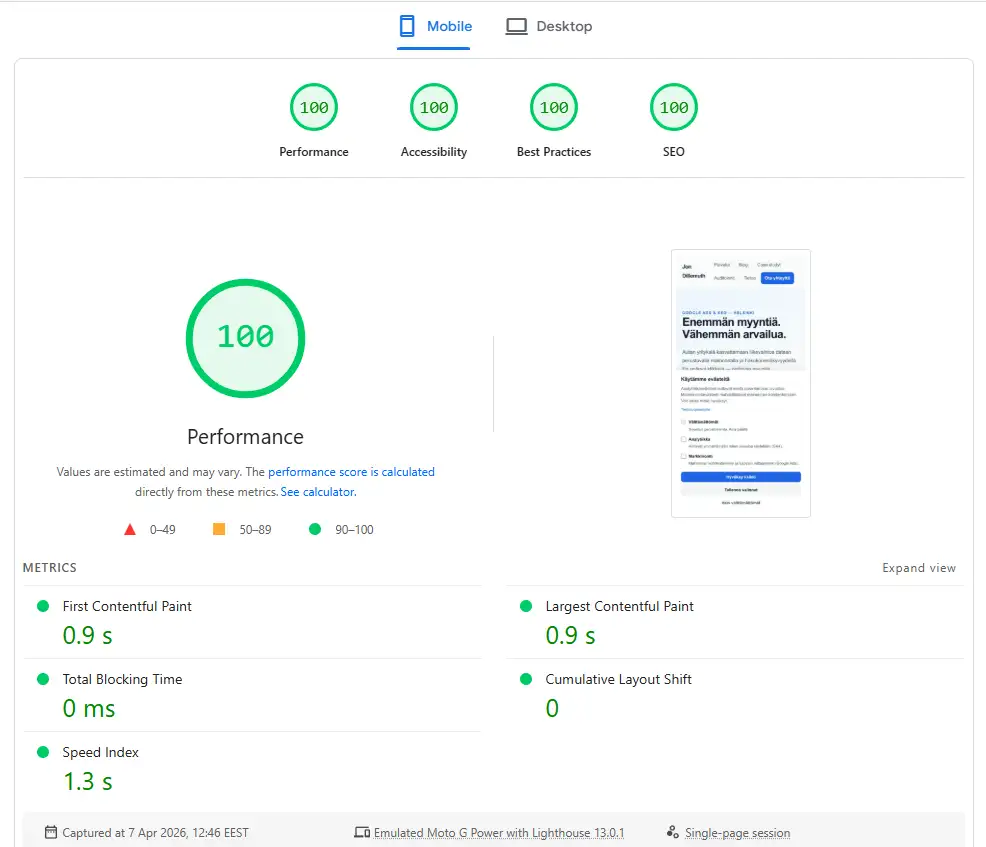
| Mittari | Lähtötilanne (mobiili) | Nykytilanne (mobiili) |
|---|---|---|
| Performance | 93/100 | 100/100 |
| LCP | 1,2 s | 0,8 s |
| CLS | 0 | 0 |
| TBT | 10 ms | 0 ms |
Mitä tehtiin 93 → 100:
- Fontin latausstrategia: vaihdettiin
font-display: swap→optionalja lisättiinpreload. Poisti FOUT-hyppyn (flash of unstyled text) ja paransi LCP:tä. - Inline CSS: kaikki tyylitiedostot inline HTML:ään (
inlineStylesheets: "always"). Poisti viimeisen render-blocking-resurssin. - Speculation Rules: lisättiin prefetch navigaatioille, jolloin seuraava sivu latautuu taustalla ennen kuin käyttäjä klikkaa.
- Kuvaoptimointi: hero-kuvalle
fetchpriority="high", muilleloading="lazy". Srcset kolmella leveydellä.
Jokainen yksittäinen muutos paransi tulosta 1–3 pistettä. Yhdessä ne veivät 93:sta sataan. (Tarkista nykytilanne PageSpeed Insightsilla)
Muut tekniset optimoinnit tällä sivustolla
Core Web Vitals on vain yksi osa teknistä SEO:ta. Tässä muut optimoinnit, joita olemme tehneet tälle sivustolle:
Schema-arkkitehtuuri (Googlen ohjeistuksen mukaan):
- WebSite- ja Organization-schema vain etusivulla, ei joka sivulla (Googlen suositus; toistaminen ei ole haitallista mutta tarpeetonta)
- Jokainen entiteetti (Organization, Person, LocalBusiness) määritelty kerran
@id:lla etusivulla (selkeyttää ylläpitoa) - Sisäsivujen WebPage viittaa etusivun WebSiteen
isPartOf-kentällä - BlogPosting.author ja .publisher viittaavat
@id:llä, eivät toista koko entiteettiä - Kaikki schemat yhdistetty
@graph-lohkoon yhteen JSON-LD-tagiin
Sitemap ja indeksointi:
- Sitemap sisältää vain indeksoitavat sivut (blogit, palvelut, case studyt, auditoinnit)
lastmod-päivämäärä päivittyy vain kun sisältö muuttuu, ei automaattisesti joka build- Turhat sivut (404, redirectit) pidetty pois sitemapista
- Case studyt ja auditoinnit lisätty sitemappiin erikseen, koska Astro ei generoi niitä automaattisesti
Redirect-hallinta:
- Canonical-slugit käytössä: esim.
/blogi/backlink-strategiat/on canonical, ja aiempi vuosiversio ohjattiin siihen 301-uudelleenohjauksella - Trailing slash -normalisointi Astro-konfiguraatiossa (
trailingSlash: "always")
Tietoturva:
- HSTS preload päällä (
includeSubDomains; preload) - Preconnect-tagit kolmannen osapuolen palvelimille (GTM, Cookiebot) vähentävät DNS-viivettä
CLS-optimointi fontille:
size-adjust-fallback-fontti estää layout shiftin latauksen aikana (CLS 0,016 → 0)font-display: optionalvarmistaa, ettei fontti aiheuta visuaalista hyppyä
Nämä optimoinnit ovat yksittäin pieniä, mutta yhdessä ne rakentavat teknisen perustan, jonka päälle sisältötyö tuottaa tulosta.
Kuvien optimointi teknisessä SEO:ssa
Kuvat ovat usein teknisen SEO:n helpoin voitto. Ne vaikuttavat latausnopeuteen, LCP-mittariin, saavutettavuuteen ja siihen, ymmärtääkö Google sivun visuaalisen sisällön.
Hyvä kuvaoptimointi ei tarkoita, että kaikki kuvat puristetaan mahdollisimman pieniksi. Se tarkoittaa, että selain saa oikeankokoisen kuvan oikeassa formaatissa, ja Google saa kuvalle ymmärrettävän kontekstin.
| Tarkistus | Hyvä toteutus | Miksi tärkeä |
|---|---|---|
| Formaatti | AVIF tai WebP, fallback tarvittaessa | Pienempi tiedostokoko ilman näkyvää laadun heikkenemistä |
| Mitat | width, height tai CSS aspect-ratio jokaiselle kuvalle | Estää CLS-hypyt latauksen aikana |
| Responsiivisuus | srcset ja sizes eri näytöille | Mobiilikäyttäjä ei lataa desktop-kokoista kuvaa |
| Lazy load | loading="lazy" kuville, jotka eivät näy heti | Säästää kaistaa ja nopeuttaa ensimmäistä näkymää |
| LCP-kuva | fetchpriority="high" ja ei lazy loadia hero-kuvalle | Suurin näkyvä elementti latautuu nopeammin |
| Alt-teksti | Kuvaa kuvan sisällön ja tarkoituksen | Parantaa saavutettavuutta ja auttaa kuvahaussa |
| Tiedostonimi | kuvaava nimi, esimerkiksi tekninen-seo-screaming-frog-crawl.webp | Antaa lisäkontekstia kuvan aiheesta |
Yleinen virhe on lisätä loading="lazy" myös hero-kuvalle. Se hidastaa LCP:tä, koska selain saa kuvan latausluvan liian myöhään. Toinen yleinen virhe on jättää kuville mitat määrittämättä. Silloin teksti hyppii kuvan latautuessa, ja CLS heikkenee.
Kuvien alt-teksteissä kannattaa olla tarkka mutta ei keinotekoinen. Screaming Frog -crawl, jossa näkyy statuskoodit ja indeksoitavuus on hyödyllinen. tekninen hakukoneoptimointi tekninen SEO Google hakukoneoptimointi on avainsanatäyttöä, eikä auta käyttäjää.
Mobiili-first-indeksointi
Google on käyttänyt 100 % mobile-first-indeksointia heinäkuusta 2024 alkaen. Mobiiliversio on se versio, jota Google arvioi.
Google käyttää sivuston mobiiliversiota indeksoinnin ja sijoitusten perustana (Googlen mobile-first-dokumentaatio). Tämä tarkoittaa:
- Jos mobiiliversiosta puuttuu sisältöä, joka on desktopversiossa, Google ei näe sitä
- Jos mobiilisivusto on hidas, se vaikuttaa sijoituksiin myös desktophaussa
- Meta-tagit (title, description, canonical) pitää olla samat mobiili- ja desktopversiossa
Responsive design (yksi HTML, CSS mukauttaa näkymän) on suositeltavin ratkaisu. Erillinen mobiilisivusto (m.domain.fi) vaatii hreflang- ja canonical-konfiguraation ja on altis virheille. Kolmas vaihtoehto, dynaaminen tarjoilu (sama URL, eri HTML mobiilille ja desktopille), on ylläpidollisesti vaikein ja alttein virheille. Google suosittelee responsive designia.
Käytännön vaikutus: jos mobiiliversiosta puuttuu sisältöä, joka näkyy desktopilla (esimerkiksi taulukot, FAQ-osiot tai sisäiset linkit piilotetaan mobiilissa CSS:llä), Google ei indeksoi puuttuvaa sisältöä. Tarkista Chrome DevToolsin mobiiliemulaatiolla (F12 > Toggle Device Toolbar), näkyykö kaikki tärkeä sisältö myös mobiilissa.
Tämän sivuston mobiilitilanne (SF, 19.4.2026): 0 “Viewport Not Set”, 0 “Content Not Sized Correctly”, 0 “Illegible Font Size”, 0 “Target Size” -ongelmia. Kaikki 32 sivua läpäisevät mobiilitarkistuksen. Syy: Astro + Tailwind CSS tuottaa responsiivisen layoutin, jossa breakpointit ja fonttikoot on määritelty design systemissa eikä yksittäisissä komponenteissa.
Responsiivisuus ja mobiilikäytettävyys
Pelkkä responsiivisuus ei riitä. Google arvioi myös mobiilikäyttökokemuksen yksityiskohtia:
- Tap target -koko: painikkeet ja linkit vähintään 48x48 pikseliä ja riittävä väli toisiinsa (8 px). Liian pienet tai lähellä olevat elementit tuottavat Lighthouse-varoituksen.
- Luettava teksti ilman zoomausta: vähimmäiskoko 16 px. Jos käyttäjän pitää nipistää zoomia, sivusto ei ole mobiiliystävällinen.
- Ei horisontaalista scrollausta: elementit eivät saa levitä näkymän ulkopuolelle.
- Häiritsevät interstitiaalit: Google rankaisee mobiilisivuja, joilla koko ruudun peittävä popup estää sisällön näkemisen heti sivun latauduttua. Tyypillisiä esimerkkejä ovat uutiskirjetarjoukset ja mainosbannerit. Pienet, helposti suljettavat bannerit ja lakisääteiset ilmoitukset (kuten evästesuostumus) ovat sallittuja.
HTTPS ja tietoturvaheaderit
HTTPS on perusedellytys, ei kilpailuetu. Vuonna 2026 ilman SSL-sertifikaattia selaimet näyttävät varoituksen, eikä Google indeksoi HTTP-sivuja samalla prioriteetilla.
HTTPS on ollut Googlen rankkaussignaali vuodesta 2014. Pelkkä sertifikaatti ei riitä: tietoturvaheaderit (HSTS, CSP) vahvistavat luottamussignaalia.
Tämän sivuston turvallisuustilanne (SF, 19.4.2026): 100 % HTTPS, 0 mixed content -varoitusta, 0 HTTP-URL:a, HSTS preload päällä (includeSubDomains). Screaming Frog Security-osio: 0 puuttuvia turvallisuusheadereita. 1 “Unsafe Cross-Origin Link” (matala prioriteetti, koskee legacy-selaimia). SPF ja DMARC DNS-tietueissa kunnossa.
Jos olet tekemässä muutosta WordPressissä, lue erillinen ohje: WordPress HTTPS käyttöön: SSL, ohjaukset ja SEO. Siinä järjestys käydään läpi WordPressin URL-asetuksista mixed content -korjauksiin ja Search Consoleen.
Perustaso
- SSL-sertifikaatti: Let’s Encrypt tarjoaa ilmaiseksi, useimmat hostingit asentavat automaattisesti
- HTTP→HTTPS redirect: 301-uudelleenohjaus kaikesta HTTP-liikenteestä HTTPS:ään
- HSTS: pakottaa selaimen käyttämään HTTPS:ää (includeSubDomains + preload suositeltuja)
- Mixed content: HTTPS-sivusto ei saa ladata resursseja (kuvia, skriptejä, CSS:ää) HTTP:llä. Selain estää tai varoittaa, ja Lighthouse pudottaa Best Practices -pistemäärää. Tarkista Chrome DevToolsin Console-välilehdeltä “Mixed Content” -varoitukset.
Lisäheaderit (eivät vaikuta suoraan sijoituksiin, mutta parantavat turvallisuutta)
| Header | Mitä tekee |
|---|---|
| Content-Security-Policy | Rajoittaa mistä sivusto voi ladata resursseja (estää XSS-hyökkäyksiä) |
| X-Content-Type-Options: nosniff | Estää MIME-type-sniffauksen |
| X-Frame-Options: SAMEORIGIN | Estää sivun upottamisen iframeen toisella sivustolla |
| Referrer-Policy | Kontrolloi mitä tietoa lähetetään kun käyttäjä klikkaa linkkiä |
Sähköpostitodennus
SPF, DKIM ja DMARC eivät ole teknistä SEO:ta perinteisessä mielessä, mutta ne vaikuttavat E-E-A-T-luotettavuuteen. Jos yrityksesi domain lähettää sähköpostia (tarjoukset, uutiskirjeet, raportit), näiden pitää olla kunnossa.
Mitä rakennedata tarkoittaa teknisessä SEO:ssa?
Rakennedata (Schema Markup) on JSON-LD-muotoinen merkintä, joka kertoo Googlelle sivun sisällön tyypistä: artikkeli, yritys, palvelu, FAQ tai henkilö. Se ei suoraan nosta orgaanisia sijoituksia, mutta mahdollistaa rich resultit hakutuloksissa: FAQ-laajennukset, tähtiarvostelut, breadcrumbit ja artikkelitiedot. Rich resultit parantavat CTR:ää ja auttavat AI-hakujärjestelmiä tunnistamaan sivustosi entiteetit.
Rakennedata auttaa Googlea tunnistamaan sivustosi entiteetit (yritys, henkilö, palvelu, artikkeli). Google suosittelee Organization- ja WebSite-schemat vain etusivulle, ei joka sivulle. Google käsittelee strukturoidun datan sivu kerrallaan eikä yhdistä @id-viittauksia eri sivujen välillä, mutta selkeä schema-arkkitehtuuri helpottaa ylläpitoa ja varmistaa, että jokainen sivu tarjoaa oikeat tiedot.
Tärkeimmät schema-tyypit yrityksille
| Tyyppi | Käyttökohde | Rich result |
|---|---|---|
| Organization | Etusivu: yrityksen nimi, logo, yhteystiedot | Knowledge Panel |
| LocalBusiness | Paikalliset yritykset: osoite, aukioloajat, palvelualue | Google Maps, Local Pack |
| FAQPage | Sivut joilla on kysymys-vastaus-osio. Rajoitettu vain gov/healthcare-sivustoille elokuusta 2023. | Ei enää yleisessä käytössä |
| Article / BlogPosting | Blogiartikkelit: kirjoittaja, julkaisuaika, kuva | Artikkelin metatiedot |
| HowTo | Vaiheittaiset ohjeet | Ei käytännössä rich result -hyötyä useimmille sivustoille |
| BreadcrumbList | Navigaatiopolku | Breadcrumb hakutuloksessa |
| Service | Palvelusivut: palvelun tyyppi, hinta, alue | Palvelun tiedot |
Toteutus
Rakennedata lisätään JSON-LD-muodossa sivun <head>-osioon. Tämä on Googlen suosittelema tapa (Microdata ja RDFa toimivat myös, mutta JSON-LD on selkein).
Validoi aina: Google Rich Results Test tai Schema Markup Validator.
Validointitulos omalle sivustolle (Screaming Frog, 19.4.2026): 32/32 sivua sisältää JSON-LD-schemaa. 0 validointivirheitä, 0 parse-virheitä, 0 validation warningia. 1 Rich Result -varoitus (VideoObject puuttuu duration yhdeltä sivulta, suositeltu muttei pakollinen). Rich Result Feature tunnistettu kaikilla 32 sivulla. Tähän päästiin sillä, että schema-arkkitehtuuri on keskitetty: entiteetit (Organization, Person, LocalBusiness) määritellään kerran @id:lla, ja muut sivut viittaavat niihin.
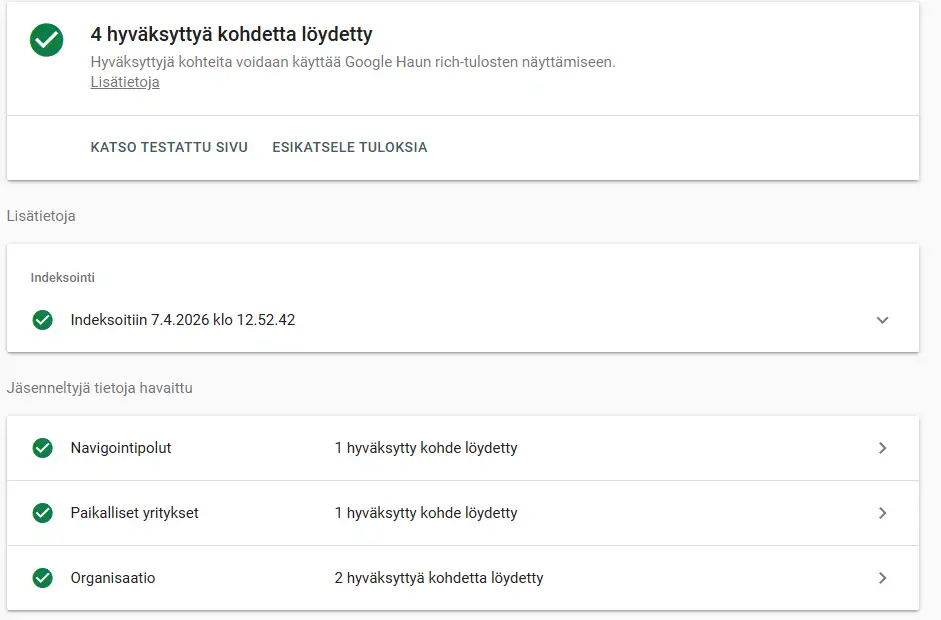
Käytännön esimerkki: tämän sivuston etusivulla on 6 schema-tyyppiä (Organization, WebSite, WebPage, BreadcrumbList, Person, LocalBusiness) ja jokaisella artikkelilla BlogPosting-schema. Sama perusmalli kannattaa rakentaa ensin tärkeimmille palvelusivuille ja vasta sen jälkeen laajentaa blogiartikkeleihin.
Sivuarkkitehtuuri ja sisäinen linkitys
Sivuarkkitehtuuri tarkoittaa, miten sivut on järjestetty ja miten ne linkittävät toisiinsa. Hyvä arkkitehtuuri palvelee sekä käyttäjiä (löytävät etsimänsä) että Googlebotia (crawlaa tehokkaasti).
Crawl depth
Crawl depth kertoo, kuinka monta klikkausta etusivulta vaaditaan tietylle sivulle pääsemiseksi. Yleissääntö: tärkeät sivut pitäisi olla saavutettavissa enintään kolmella klikkauksella.
Tämän sivuston crawl depth (SF, 19.4.2026): 1 sivu syvyydellä 0 (etusivu), 14 sivua syvyydellä 1 (palvelut, blogi-index, case studyt), 18 sivua syvyydellä 2 (yksittäiset artikkelit). 0 sivua syvyydellä 3 tai enemmän. Tämä tarkoittaa, että jokainen sivu on saavutettavissa kahdella klikkauksella etusivulta. Syy: header-navigaatio linkittää kaikkiin kategoriasivuihin (syvyys 1), ja kategoriasivut linkittävät kaikkiin artikkeleihin (syvyys 2).
Sisäinen linkitys
Sisäiset linkit jakavat link equityä (sivun “arvovaltaa”) sivulta toiselle. Käytännön periaatteet:
- Jokaisella sivulla vähintään yksi sisäinen linkki (ei orphan-sivuja)
- Ankkuriteksti on kuvaava: “lue lisää hakukoneoptimoinnista” on parempi kuin “klikkaa tästä”
- Linkitä aiheenmukaisesti: SEO-artikkeli linkittää toisiin SEO-artikkeleihin ja SEO-palvelusivulle
- Navigaatio on johdonmukainen: header, footer ja breadcrumbit muodostavat sivuston rungon
Sisäisen linkityksen data (SF, 19.4.2026): Sivuston 12 eniten linkitettyä sivua saavat kukin 33/33 inlinkkiä (= jokaiselta HTML-sivulta). Nämä ovat navigaatiosivuja: etusivu, palvelut, blogi, case studyt, yhteystiedot. Sisältölinkit jakautuvat eri tavalla: hakukoneoptimointi-opas saa 15 content-linkkiä, avainsanatutkimus-opas 12 ja tekninen SEO -opas 11. Tämä heijastaa pillar-cluster-rakennetta: pillar-sivut keräävät eniten sisäisiä linkkejä. 0 orphan-sivuja (jokainen sivu saa vähintään yhden linkin).
Breadcrumb-navigaatio
Breadcrumbit (leipämurupolut) ovat navigaatioelementti, joka näyttää käyttäjälle missä kohtaa sivuston hierarkiaa hän on: Etusivu > Blogi > Tekninen SEO. Ne hyödyttävät sekä käyttäjiä että hakukoneita:
- Käyttäjälle: selkeä käsitys sijainnista ja helppo navigointi ylöspäin hierarkiassa
- Googlelle: ymmärtää sivuston rakenteen ja voi näyttää breadcrumbit hakutuloksissa URL:n sijaan
- Link equity: breadcrumbit jakavat link equityä ylöspäin hierarkiassa (jokainen alasivu linkittää kategoriasivuun ja etusivuun)
Toteutus: HTML-elementti sivun yläosassa + BreadcrumbList-schema JSON-LD:ssä. WordPress-pluginit (Yoast, Rank Math) generoivat molemmat automaattisesti.
Pillar-cluster-malli
Tehokas tapa järjestää sisältö on pillar-cluster-malli:
- Pillar-sivu kattaa laajan aiheen kokonaisuutena
- Klusterisivut syventävät yksittäisiä osa-alueita
- Pillar linkittää kaikkiin klustereihin, klusterit linkittävät takaisin pillariin
- Palvelusivu on konversion kohde, johon sekä pillar että klusterit ohjaavat
Tämä rakenne osoittaa Googlelle, että sivusto on aiheensa asiantuntija (topical authority).
Miten JavaScript-renderöinti vaikuttaa indeksointiin?
Staattinen HTML indeksoituu Googlen toimesta tyypillisesti vuorokaudessa. JavaScript-renderöity sisältö siirtyy erilliseen rendering-jonoon ja voi jäädä näkymättömissä päiviksi tai viikoiksi julkaisun jälkeen. Tämä on merkittävin tekninen SEO-riski SPA-sovelluksissa (React, Vue, Angular). Ratkaisu: SSR tai SSG.
Google pystyy renderöimään JavaScriptiä (eli suorittamaan sivuston JS-koodin ja näkemään lopputuloksen), mutta se tekee sen viiveellä.
Käytännön vaikutukset
- Client-side rendering (CSR): React SPA, jossa sisältö renderöidään selaimessa. Google näkee sen, mutta viiveellä. Huonoin vaihtoehto SEO:lle.
- Server-side rendering (SSR): Palvelin tuottaa valmiin HTML:n jokaisella pyynnöllä. Google näkee sisällön heti.
- Static site generation (SSG): Build-vaiheessa tuotettu valmis HTML. Paras vaihtoehto SEO:lle. Astro, Hugo, Next.js (static export).
Jos sivustosi käyttää Reactia, Vueta tai Angularia, varmista SSR tai SSG. Puhdas CSR on SEO-riski.
Tämän sivuston tilanne: Astro tuottaa 100 % staattista HTML:ää build-vaiheessa (SSG). Screaming Frog -crawlissa (19.4.2026): 1 sivu sisältää JavaScript-linkkejä, 1 sivu JavaScript-sisältöä (molemmat BookingWidget-varauskomponentissa). Kaikki muu sisältö on staattista HTML:ää, jonka Google näkee heti ilman renderöintiä. Tämä on ideaalitilanne: 0 JS-riippuvuuksia kriittisessä sisällössä.
Renderöintiviive käytännössä
Uusi JavaScript-renderöity sivu voi jäädä näkymättömiin haussa jopa 2 viikkoa julkaisun jälkeen. Staattinen HTML indeksoituu tyypillisesti päivässä. Tämä ero on kriittinen kampanjasivuille, ajankohtaisille artikkeleille ja kausisisällöille (joulukalenteri, kesäkampanja). Jos sisältö on aikaherkää, SSR tai SSG on välttämätön.
Toinen käytännön ongelma: Google renderöi JavaScript-sivut erillisessä “rendering queue” -jonossa, joka on hitaampi kuin crawlausjono. Jos sivustosi sisältö muuttuu usein (uudet tuotteet, päivittyvät hinnat), JavaScript-pohjainen renderöinti tarkoittaa, että hakutuloksissa näkyy vanhaa tietoa pidempään.
Tarkistus
Google Search Consolen URL Inspection > “View Tested Page” näyttää, mitä Google näkee renderöinnin jälkeen. Vertaa tätä selaimen DevToolsin JavaScript-poistotilaan (Chrome: Settings > Debugger > Disable JavaScript).
Tekninen SEO ja tekoälyhaut
Tekoälyhaut (Google AI Overview, Perplexity, ChatGPT) käyttävät samaa teknistä perustaa kuin perinteinen haku. Jos Google ei pysty crawlaamaan sivustoasi, AI ei voi siteerata sitä.
AI-hakujärjestelmät eroavat perinteisestä hausta kolmella tavalla: ne tiivistävät sisällön vastaukseksi (eivät näytä pelkkää linkkiä), ne suosivat rakenteellisesti selkeää sisältöä (taulukot, listat, määritelmät) ja ne painottavat auktoriteettia (backlinkit, nimetty kirjoittaja, tuore sisältö).
Tekninen pohja on vasta lähtökohta. Kun crawlattavuus ja rakennedata ovat kunnossa, seuraava työ on tekoälyoptimointi: tärkeimpien sivujen answer-first-rakenne, luottamussignaalit ja AI-näkyvyyden mittaus.
AI-crawlerien hallinta
Vuonna 2026 robots.txt on päätöksentekopaikka AI-crawlerien suhteen. Tärkeimmät AI-crawlerit:
| Crawleri | Yritys | Tarkoitus |
|---|---|---|
| GPTBot | OpenAI | ChatGPT, koulutusdata |
| ClaudeBot | Anthropic | Claude, koulutusdata |
| PerplexityBot | Perplexity | Tekoälyhaku |
| Google-Extended | Gemini-koulutus (ei vaikuta hakuun) | |
| Bytespider | ByteDance | TikTok, koulutusdata |
Jos haluat näkyä tekoälyhauissa, älä estä näitä botteja. Jos haluat estää sisältösi käytön pelkästään koulutusaineistona (mutta sallia hakunäkyvyyden), estä Google-Extended, mutta salli GPTBot ja PerplexityBot.
llms.txt
llms.txt on vapaaehtoinen standardi, joka kertoo LLM-järjestelmille miten ne voivat käyttää sivustosi sisältöä. Se on kuin robots.txt, mutta tekoälylle. Tällä sivustolla llms.txt on toteutettu dynaamisesti (generoidaan automaattisesti build-vaiheessa).
Rehellisyyden nimissä: toistaiseksi ei ole näyttöä siitä, että llms.txt parantaisi AI-hakunäkyvyyttä tai liikennettä. Se on hyvä signaali, mutta ei prioriteetti.
Hallusinoidut URL:t
AI-järjestelmät saattavat generoida URL-osoitteita, joita ei ole olemassa sivustollasi. Esimerkiksi ChatGPT voi viitata osoitteeseen jondillemuth.fi/blogi/tekninen-seo-opas/, vaikka oikea URL on /blogi/tekninen-hakukoneoptimointi/.
Näitä voi seurata GSC:n tai analytiikan 404-raportista. Jos hallusinoitu URL saa liikennettä, ohjaa se 301-redirectillä oikeaan sivuun. Tämä on uusi ilmiö, johon kannattaa varautua erityisesti kun AI-hakujen käyttö kasvaa.
Tämän sivuston tilanne: AI-botit (GPTBot, ClaudeBot, PerplexityBot) on sallittu robots.txt:ssä. llms.txt on toteutettu. Huhtikuussa 2026 sivusto ei ole vielä siteerattu AI Overviewissa hakutermillä “tekninen hakukoneoptimointi”. Todennäköisin syy on domain auktoriteetti (1 referring domain), ei tekninen toteutus. AI Overview siteeraa 6 sivustoa, joilla kaikilla on vahvempi backlink-profiili.
Hreflang ja monikielisyys
Jos sivustolla on useita kieliversioita, hreflang-tagit kertovat Googlelle, mikä sivu on millä kielellä ja mitkä sivut ovat toistensa käännöksiä.
<link rel="alternate" hreflang="fi" href="https://domain.fi/sivu/" />
<link rel="alternate" hreflang="en" href="https://domain.fi/en/page/" />
<link rel="alternate" hreflang="x-default" href="https://domain.fi/sivu/" />Ilman hreflangia Google saattaa näyttää väärän kieliversion hakijalle. X-default kertoo, mikä versio näytetään käyttäjille, joille mikään spesifi kieliversio ei sovi.
Yksikielisellä sivustolla hreflang ei ole välttämätön, mutta sen lisääminen valmiiksi helpottaa tulevaa laajennusta.
Omasta datasta: jondillemuth.fi on yksikielinen (suomi), mutta hreflang on silti toteutettu kaikilla 32 sivulla. Screaming Frog (19.4.2026): 0 hreflang-virheitä, 0 puuttuvia return-linkkejä, 0 ristiriitaisia kielimäärittelyjä. Kun englanninkielinen versio lisätään, konfiguraatio on valmis.
Redirect-hallinta
Uudelleenohjaukset ovat väistämättömiä: URL-rakenne muuttuu, sivuja poistetaan, sisältöä yhdistetään. Oikein tehtyinä ne eivät aiheuta ongelmia.
| Tyyppi | Milloin käytetään |
|---|---|
| 301 (pysyvä) | Sisältö on siirtynyt pysyvästi. Siirtää link equityn kohteeseen. |
| 302 (väliaikainen) | Sisältö on väliaikaisesti toisessa osoitteessa. Ei siirrä link equityä. |
| Redirect-ketju | A → B → C. Jokainen hyppy menettää pienen osan link equityä. Lyhennä: A → C. |
| Redirect-looppi | A → B → A. Google lopettaa crawlauksen. Rikkoo sivun indeksoinnin. |
Tarkista redirect-tilanne Screaming Frogilla: Response Codes > Internal Redirection (3xx).
Oma esimerkki redirect-hallinnasta: Tällä sivustolla canonical-slugit ovat käytössä. Kun backlink-strategia-artikkelin URL päivitettiin nykyiseen muotoon, vanha versio ohjattiin 301:llä osoitteeseen /blogi/backlink-strategiat/. Screaming Frog -crawlissa (19.4.2026): 1 sisäinen redirect, 0 redirect-ketjuja, 0 redirect-looppeja. Yksi redirect on hyväksyttävä tila: se tarkoittaa, että URL-muutos on hallittu eikä link equity katoa.
Nyrkkisääntö: 1–2 redirectiä on normaalia. 10+ sisäistä redirectiä viittaa siihen, ettei URL-muutoksia ole suunniteltu. Redirect-ketjut (A→B→C) pitää aina lyhentää suoriksi (A→C), koska jokainen hyppy lisää latenssia ja syö crawl budgetia.
Crawl budget: milloin sillä on väliä?
Crawl budget on relevantti ongelma vasta kun sivustolla on yli 10 000 sivua tai merkittäviä indeksointiongelmia. Pienille sivustoille se ei ole käytännön rajoite.
Crawl budget tarkoittaa, kuinka monta sivua Googlebot crawlaa sivustoltasi tietyssä ajassa. Se koostuu kahdesta tekijästä: crawl capacity (kuinka paljon Google haluaa crawlata) ja crawl demand (kuinka paljon sisältöäsi on päivittynyt).
Milloin crawl budget on ongelma
- Suuret sivustot (10 000+ sivua): Jos suurin osa sivuista on parametri-URL:ja, suodatinvariantteja tai thin content -sivuja, Googlebot tuhlaa aikaa epäolennaiseen
- Hidas palvelin: Jos palvelin vastaa hitaasti, Googlebot hidastaa crawlausta automaattisesti suojellakseen palvelintasi
- Redirect-ketjut: Jokainen redirect kuluttaa crawl budgetia ilman hyötyä
Milloin se ei ole ongelma
Pk-yrityksen 30–200 sivun sivustolla crawl budget ei rajoita mitään. Google crawlaa koko sivuston joka tapauksessa. Panostus kannattaa kohdistaa sisällön laatuun ja backlinkkeihin.
Oma tilanne: jondillemuth.fi: 32 HTML-sivua. Crawl budget ei ole ongelma. Screaming Frog -crawl kesti 3 minuuttia. Googlebot crawlaa vastaavan sivuston kokonaan päivittäin. Crawl budget -optimointi tulee relevanttiksi vasta jos sivustolle lisätään esimerkiksi automaattisesti generoituja auditointi-sivuja tai muita skaalautuvia sisältötyyppejä.
Crawl budgetin seuranta
GSC:n Crawl Stats -raportti (Settings > Crawl stats) näyttää kuinka monta sivua Google crawlaa päivittäin, keskimääräisen vastausajan ja crawlausstatukset. Seuraa erityisesti: crawlaako Google sivustoasi säännöllisesti, onko vastausaika noussut ja kasvaako “crawled, not indexed” -sivujen määrä.
Rikkinäiset sivut ja linkit
Jokainen rikkinäinen linkki on menetettyä link equityä ja huono käyttäjäkokemus. Priorisoi korjaukset sen mukaan, kuinka paljon sisäisiä ja ulkoisia linkkejä 404-sivuun osoittaa.
Rikkinäiset linkit (404-virheet) ovat yksi yleisimmistä teknisen SEO:n ongelmista. Ne syntyvät kun sivuja poistetaan, URL-rakennetta muutetaan tai ulkoiset sivustot linkittävät vanhoihin osoitteisiin.
Tämän sivuston tilanne (SF, 19.4.2026): 1 sisäinen 4xx-virhe (tunnistettu, korjausjono), 6 ulkoista 4xx-virhettä (kolmannen osapuolen sivut, jotka ovat poistuneet tai muuttaneet URL-rakennetta). Sisäiset 404:t priorisoidaan aina ensin, koska ne ovat omassa hallinnassa.
Miksi ne ovat ongelma
- Käyttäjä päätyy virhesivulle: huono kokemus, kävijä poistuu
- Link equity katoaa: ulkoiset linkit vanhoihin URL:eihin eivät siirrä arvoa mihinkään
- Crawl budget tuhlaantuu: Googlebot crawlaa sivuja, jotka palauttavat 404
Miten löytää
- GSC > Coverage > “Not found (404)”: näyttää sivut, joihin Google on yrittänyt päästä
- Screaming Frog > Response Codes > Client Error (4xx): löytää sisäiset rikkinäiset linkit
- Screaming Frog > Inlinks-raportti: näyttää mistä sivuilta 404-sivuille linkitetään
- Ahrefs/DataForSEO Broken Backlinks: löytää ulkoiset linkit, jotka osoittavat rikkinäisiin sivuihin
Miten korjata
| Tilanne | Ratkaisu |
|---|---|
| Sivu on siirtynyt uuteen osoitteeseen | 301-uudelleenohjaus vanhasta uuteen |
| Sivu on poistettu, sisältö on muualla | 301 lähimpään vastaavaan sivuun |
| Sivu on poistettu, ei korvaavaa | Palauta 410 (Gone) ja päivitä sisäiset linkit |
| Ulkoiset linkit osoittavat vanhaan osoitteeseen | 301-uudelleenohjaus + pyydä linkittäjää päivittämään |
Priorisoi korjaukset: ensin sivut, joihin tulee eniten sisäisiä ja ulkoisia linkkejä. Screaming Frogin Inlinks-sarake kertoo sisäisten linkkien määrän.
Teknisen SEOn mittaaminen
Mittaamaton tekninen SEO on arvailua. Ilman ennen/jälkeen-vertailua et tiedä, paransiko muutos mitään vai rikkoiko se jotain.
Oma mittauskäytäntö: Tällä sivustolla Screaming Frog -crawl ajetaan viikoittain ja tulokset tallennetaan vertailua varten. Edellinen crawl (16.4.2026): 28 HTML-sivua, 20 Rich Result -varoitusta. Tuore crawl (19.4.2026): 32 HTML-sivua (+4 uutta), 1 Rich Result -varoitus (-19). Schema-korjaukset (author → Person, LocalBusiness-geo lisätty) näkyvät suoraan varoitusten putoamisena. Tämä on se tapa, jolla tekniset muutokset validoidaan: data ennen, data jälkeen.
Mitä mitata
| Mittari | Työkalu | Miksi tärkeä |
|---|---|---|
| Indeksoidut sivut | GSC Coverage | Kasvaako vai pieneneekö? Virhetrendit? |
| Crawlaus-tilastot | GSC Crawl Stats | Crawlaako Google sivustoasi säännöllisesti? |
| Core Web Vitals (kenttädata) | GSC CWV -raportti, CrUX | Googlen käyttämä rankkaussignaali |
| Orgaaninen liikenne | GA4 (orgaaninen kanava) | Näkyykö tekninen korjaus liikenteen kasvuna? |
| 404-virheet | GSC Coverage, Screaming Frog | Laskeeko virhemäärä korjausten jälkeen? |
| Schema-virheet | GSC Enhancements | Toimiiko rakennedata oikein? |
Mittauskehys
- Dokumentoi lähtötilanne ennen muutoksia: ota kuvakaappaus GSC:n Coverage-raportista ja CWV-mittareista
- Tee yksi muutos kerrallaan: jos muutat kaiken yhtä aikaa, et tiedä mikä vaikutti
- Odota 2–4 viikkoa: Google ei reagoi välittömästi. Crawlaus, indeksointi ja uudelleenarviointi vievät aikaa
- Vertaa ennen/jälkeen: samat mittarit, sama ajanjakso. GSC:ssä vertaa “viimeiset 3 kk” edelliseen 3 kk:een
- Yhdistä liiketoimintaan: tekninen parannus → indeksointi kasvaa → orgaaninen liikenne kasvaa → konversiot kasvavat
Käytännön esimerkkejä: tekninen SEO toimenpiteissä
Teoria on hyödyllistä, mutta konkreettiset esimerkit kertovat enemmän. Tässä kaksi tapausta tältä sivustolta.
Esimerkki 1: Schema-arkkitehtuurin korjaus (3 päivässä)
Lähtötilanne (16.4.2026): Screaming Frog -crawl raportoi 20 Rich Result -varoitusta 28 sivulla. Suurimmat ongelmat: BlogPosting-sivujen author-kenttä oli merkkijono (“Jon Dillemuth”) eikä Person-entiteetti, ja LocalBusiness-schemasta puuttui geo-koordinaatit 5 palvelusivulla.
Toimenpide: Kolme muutosta koodiin:
- Author-schema muutettiin Person-entiteetiksi
@id-viittauksella (yksi muutos layout-tiedostoon, vaikutti kaikkiin 15+ artikkeliin) - LocalBusiness-schemaan lisättiin
geo-koordinaatit jaopeningHoursSpecification - ProfessionalService-schemaan samat korjaukset
Tulos (19.4.2026): Rich Result -varoitukset 20 → 1 (jäljellä vain VideoObject duration, joka on suositeltu muttei pakollinen). Korjaus kesti yhden tunnin, koska schema-arkkitehtuuri on keskitetty: entiteetit määritellään kerran, ja muut sivut viittaavat @id:llä. Jos jokainen sivu olisi sisältänyt oman kopion schemasta, sama korjaus olisi vaatinut 28 erillistä muokkausta.
Oppi: Keskitetty schema-arkkitehtuuri (@id-viittaukset, @graph-lohko) tekee korjaamisesta skaalautuvan. Yksi muutos → vaikuttaa kaikkiin sivuihin.
Esimerkki 2: WordPress-sivuston robots.txt-ongelma (asiakastapaus)
Tilanne: WordPress-sivusto, jossa liikenne laski 40 % kuukaudessa. GSC Coverage -raportti näytti “Blocked by robots.txt” kahdeksalle sivulle.
Juurisyy: Sivuston kehittäjä oli lisännyt Disallow: /wp-content/uploads/ robots.txt-tiedostoon estääkseen kuvakansion crawlauksen. Tarkoitus oli hyvä (säästää crawl budgetia), mutta seuraus oli se, ettei Google voinut renderöidä yhtäkään sivua oikein, koska kuvat eivät latautuneet.
Korjaus: Robots.txt-rivi poistettiin. 2 viikon sisällä Google crawlasi ja renderöi sivut uudelleen kuvien kanssa. Liikenne palautui 3 viikossa edelliselle tasolle.
Oppi: Robots.txt ei ole turvatyökalu. Älä estä resursseja (CSS, JS, kuvat), joita Google tarvitsee sivun renderöintiin. Tarkista aina GSC:n URL Inspection -työkalulla, näkeekö Google sivun samalla tavalla kuin käyttäjä.
Teknisen SEOn tarkistuslista
Priorisoitu lista jokaisen sivuston omistajan tarkistettavaksi:
Kriittinen (tarkista heti)
- Google Search Console on käytössä ja vahvistettu
- Sivut indeksoituvat (GSC Coverage-raportti)
- HTTPS toimii ja HTTP ohjaa 301:llä HTTPS:ään
- Robots.txt ei estä tärkeitä sivuja
- XML-sitemap on olemassa ja lähetetty GSC:hen
- Ei 404-virheitä sisäisissä linkeissä
- URL-rakenne on puhdas ja looginen (ei
?p=123, ei turhia parametreja) - Vain yksi versio sivustosta saavutettavissa (www/ei-www, HTTP/HTTPS)
Tärkeä (tarkista kuukausittain)
- Core Web Vitals vihreällä (LCP < 2,5s, INP < 200ms, CLS < 0,1)
- Kaikilla sivuilla on self-referencing canonical
- Kaikilla sivuilla on title, H1 ja meta description
- Kuvilla on alt-teksti ja width/height
- Ei redirect-ketjuja tai -looppeja
- Schema validoitu ilman virheitä (WebSite vain etusivulla)
- Ei duplikaattisisältöä (tarkista Screaming Frog > URL > Duplicate)
- Ei mixed content -varoituksia (HTTPS-sivu ei lataa HTTP-resursseja)
- Mobiilisivulla ei häiritseviä interstitiaaleja (koko ruudun peittäviä popuppeja)
Hyvä tietää (tarkista kvartaaleittain)
- Tietoturvaheaderit (HSTS, CSP, X-Content-Type-Options)
- SPF ja DMARC DNS-tietueissa
- Orphan-sivuja ei ole (jokainen sivu saa vähintään yhden sisäisen linkin)
- Crawl depth alle 4 tärkeille sivuille
- Hreflang oikein (jos monikielinen)
- Breadcrumbit toimivat ja BreadcrumbList-schema validoitu
- AI-crawlerien hallinta robots.txt:ssä (GPTBot, ClaudeBot) tietoinen päätös
- CDN ei estä AI-botteja automaattisesti (tarkista Cloudflare Bot Management)
- Hallusinoidut URL:t tarkistettu 404-raportista ja ohjattu 301:llä
Työkalut
| Työkalu | Mitä tekee | Hinta |
|---|---|---|
| Google Search Console | Indeksointi, kyselyt, CWV kenttädata, URL Inspection | Ilmainen |
| PageSpeed Insights | CWV lab-mittaukset, optimointiehdotukset | Ilmainen |
| Screaming Frog | Sivuston crawlaus: linkit, canonicalit, schemat, statuskoodit | Ilmainen (500 URL), Pro 279 $/v |
| Google Rich Results Test | Schema-validointi ja rich result -esikatselu | Ilmainen |
| Ahrefs Site Audit | Automaattinen tekninen auditointi | Alkaen 29 $/kk (Starter) |
| Chrome DevTools | Lighthouse, Network-analyysi, JS-debuggaus | Ilmainen |
Useimmille pk-yrityksille riittävät ilmaiset työkalut: GSC + PageSpeed Insights + Screaming Frog (500 URL:n ilmaisversio).
Miten valita oikea työkalu? GSC on pakollinen jokaiselle sivustolle, koska se on ainoa lähde indeksointidataan ja kenttäpohjaisiin CWV-metriikoihin. PageSpeed Insights riittää nopeuden diagnostiikkaan. Screaming Frog on paras crawl-työkalu: se löytää rikkinäiset linkit, duplikaatit, puuttuvat canonicalit ja schema-virheet yhdellä crawlilla. Ahrefs tai Semrush kannattaa lisätä vasta kun tarvitset backlink-dataa tai kilpailija-analyysia. Älä aloita kalliista työkaluista. Aloita ilmaisista, ja lisää maksullisia vasta kun tiedät, mitä etsit.
Milloin tekninen SEO kannattaa ostaa palveluna?
Teknisen SEO:n perustarkistukset voi tehdä itse. Palveluna se kannattaa ostaa silloin, kun ongelma vaikuttaa jo euroihin tai riski on liian iso arvailtavaksi.
Tyypillisiä tilanteita:
- Orgaaninen liikenne on laskenut, eikä syy näy suoraan sisällöstä
- Sivusto on juuri uudistettu, siirretty uudelle alustalle tai URL-rakenne on muuttunut
- Google Search Console näyttää paljon indeksointi-, canonical- tai 404-ongelmia
- Sivusto on hidas mobiililla, mutta kehittäjät eivät ole varmoja juurisyystä
- Verkkokaupassa suodattimet, kategoriat tai tuotevariantit tuottavat tuhansia URL:eja
- AI-hakunäkyvyys, schema ja entiteettirakenne halutaan rakentaa samalla kertaa kuntoon
Hyvä tekninen SEO-auditointi ei ole lista sadasta irrallisesta virheestä. Sen pitää kertoa, mikä estää näkyvyyttä, mikä heikentää konversiota ja missä järjestyksessä korjaukset kannattaa tehdä. Jos tarvitset tähän ulkopuolisen näkymän, hakukoneoptimointi yritykselle on yleensä järkevämpi ostos kuin uuden työkalun kuukausimaksu.
Usein kysytyt kysymykset teknisestä SEO:sta
Mitä eroa on teknisellä SEO:lla ja sisältö-SEO:lla?
Tekninen SEO varmistaa, että Google löytää ja indeksoi sivustosi. Sisältö-SEO varmistaa, että löydetty sisältö vastaa hakijan tarpeeseen. Käytännön esimerkki: tekninen perusta (nopeus, crawlattavuus, canonical) mahdollistaa sen, että sisältö nousee hakutuloksissa. Ilman tätä perustaa artikkelit jäävät indeksoimatta tai latautuvat liian hitaasti.
Kuinka usein tekninen SEO-auditointi pitäisi tehdä?
Pikainen tarkistus kuukausittain: GSC-virheet ja Core Web Vitals. Perusteellinen auditointi 2–4 kertaa vuodessa tai aina kun sivusto läpikäy suuren muutoksen: alustavaihto, redesign tai uuden sisältöosion lisääminen.
Voinko tehdä teknisen SEO-auditoinnin itse?
Perustarkistukset kyllä. Google Search Console, PageSpeed Insights ja Screaming Frog ilmaisversio (500 URL) kattavat 80 % tarkistuksista. Syvällisempi auditointi vaatii kokemusta: JavaScript-renderöinnin tarkistus, redirect-ketjujen analyysi, log file -tulkinta ja schema-arkkitehtuurin suunnittelu ovat asioita, joissa virhe voi aiheuttaa enemmän haittaa kuin hyötyä.
Miten Core Web Vitals vaikuttaa sijoituksiin?
Core Web Vitals on tiebreaker: kun kaksi sivua on sisällöltään tasavertaista, nopeampi voittaa. CWV ei yksinään nosta sivua kärkeen, mutta erittäin huono CWV (LCP yli 4 sekuntia, CLS yli 0,25) voi pudottaa sijoituksia merkittävästi.
Pitääkö sivusto rakentaa uudelleen, jos tekninen SEO on huonossa kunnossa?
Harvoin. Useimmat ongelmat korjataan konfiguraatiomuutoksilla, ei uudelleenrakentamisella. Yleisimmät korjaukset ovat kuvien optimointi, käyttämättömän JavaScriptin poisto, canonical-tagien lisääminen ja redirect-ketjujen lyhentäminen.
Mikä on crawl budget ja pitääkö siitä huolehtia?
Crawl budget tarkoittaa, kuinka monta sivua Google crawlaa sivustoltasi tietyssä ajassa. Alle 10 000 sivun sivustoilla se ei ole käytännössä ongelma. Suuremmilla sivustoilla ohjaa crawl budgetia: estä turhat sivut robots.txt:llä, korjaa redirect-ketjut ja pidä sitemap ajan tasalla.
Vaikuttaako hosting-palvelu tekniseen SEO:hon?
Kyllä, epäsuorasti. Nopea palvelin parantaa TTFB:tä, joka vaikuttaa LCP:hen. CDN-verkko (Cloudflare, Netlify, Vercel) jakaa sisällön globaalisti ja vähentää latenssia. Jaettu hosting hidastaa sivustoa kuormituspiikkien aikana.
Mikä on pagination ja miten se vaikuttaa SEO:hon?
Pagination jakaa pitkän sisältölistan usealle sivulle. Google osaa crawlata paginoituja sivuja, kunhan jokainen sivu on linkitetty edelliseen ja seuraavaan. Infinite scroll on SEO-riski, koska Google ei suorita scrollausta. Jos käytät infinite scrollia, varmista, että sisältö on saatavilla myös paginoituina sivuina.
Tarvitseeko tekniseen SEO:hon ohjelmointiosaamista?
Perustarkistuksiin ei. Google Search Console, PageSpeed Insights ja Screaming Frog toimivat ilman koodaustaitoja. Suurin osa korjauksista (robots.txt, meta-tagit, schema) onnistuu WordPress-plugineilla. Syvällisempi työ, kuten JavaScript-renderöinnin optimointi tai palvelinlogiikka, vaatii kehittäjäosaamista.
Eroaako verkkokaupan tekninen SEO palvelusivuston teknisestä SEO:sta?
Perusperiaatteet ovat samat, mutta verkkokaupassa korostuvat: duplikaattisisältö (sama tuote useassa kategoriassa), suodattimet ja URL-parametrit (väri, koko, hinta luovat tuhansia URL-variantteja), Product-schema sekä sivuston koko (tuhannet tuotesivut vaativat crawl budgetin hallintaa).
Miten tekninen SEO vaikuttaa tekoälyhakuihin?
AI-hakujärjestelmät (Google AI Overview, Perplexity, ChatGPT) käyttävät samoja perusedellytyksiä kuin perinteinen haku: sivuston pitää olla crawlattavissa, nopeasti latautuva ja rakenteellisesti selkeä. Rakennedata auttaa AI-järjestelmiä tunnistamaan sisällön entiteetit. Hyvä tekninen SEO parantaa automaattisesti myös AI-hakunäkyvyyttä.
Mitä tehdä sivuille, joilla on liian vähän sisältöä?
Thin content tarkoittaa sivuja, joilla on niin vähän tekstiä, ettei Google pidä niitä riittävän arvokkaana indeksoitavaksi. Ratkaisu riippuu sivutyypistä: listasivuille lisätään kuvaava intro-teksti, turhille sivuille asetetaan noindex ja arvokkaille mutta ohuille sivuille kirjoitetaan lisää substanssia. Screaming Frog tunnistaa thin content -sivut Content-välilehdeltä.
Tämä artikkeli on osa hakukoneoptimoinnin opasta. Lue myös: Avainsanatutkimus: käytännön opas ja Backlink-strategiat 2026.
Ilmainen kartoitus